Building a Scalable FHIR Analytics Platform with dbt, Parquet, and DuckDB
Building a Scalable FHIR Analytics Platform with dbt, Parquet, and DuckDB
In the modern healthcare technology landscape, HL7 FHIR (Fast Healthcare Interoperability Resources) has established itself as the gold standard for data exchange. Its resource-oriented approach and JSON serialization make it excellent for transactional systems and interoperability. However, when it comes to analytics, FHIR’s deeply nested structures and graph-like relationships pose significant challenges for traditional columnar analysis.
This article outlines a professional architecture for bridging the gap between operational FHIR servers and analytical needs by leveraging dbt, Parquet, and DuckDB.
The Architecture
The goal is to transform complex FHIR JSON into a flattened, columnar format optimized for OLAP (Online Analytical Processing) queries, while ensuring strict data segregation between tenants.
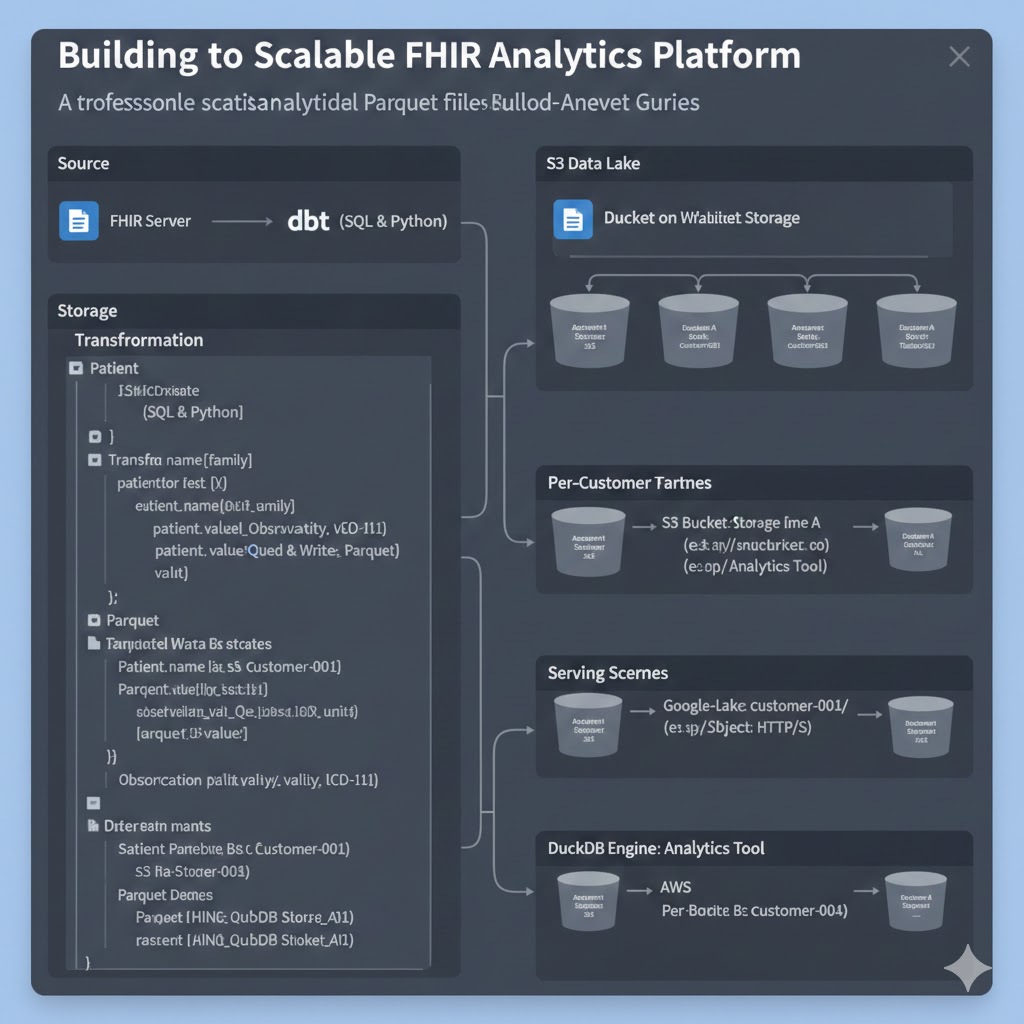
The Transformation Pipeline
1. Extraction and Transformation with dbt
The process begins with extracting resources from the FHIR server. While dbt (data build tool) is primarily a transformation tool, it orchestrates the SQL logic required to unnest and flatten FHIR resources.
Using dbt’s modular model structure, we can define transformations for each resource type (e.g., Patient, Encounter, Observation).
- Flattening: We extract high-value fields from the nested JSON (e.g.,
patient.name[0].family,observation.valueQuantity.value) into flat columns. - Standardization: dbt allows us to cast data types and normalize codes (e.g., LOINC or SNOMED) into a consistent format.
- Testing: We utilize dbt’s testing capabilities to assert data quality constraints, ensuring that the analytical data is reliable.
2. Storage: Parquet on S3
The transformed data is materialized as Parquet files. Parquet is a columnar storage format that is highly efficient for analytical queries, offering significant compression and performance benefits over JSON.
Data Segregation Strategy
A critical aspect of this architecture is multi-tenancy. Instead of commingling data in a single data warehouse schema, we leverage object storage (Amazon S3) to enforce physical segregation.
- Per-Customer Buckets: The pipeline is configured to write the output Parquet files into a dedicated S3 bucket for each customer (e.g.,
s3://data-lake-customer-001/). - Security & Compliance: This approach simplifies compliance with strict regulations like GDPR and HIPAA. Access policies (IAM) can be scoped strictly to the bucket level, ensuring that data leakage between tenants is architecturally impossible.
3. Serving with DuckDB
To query the data, we utilize DuckDB, an in-process SQL OLAP database management system. DuckDB is uniquely suited for this architecture because:
- Direct Parquet Querying: It can query Parquet files directly from S3 via HTTP/S without the need to load data into a persistent database server.
- Vectorized Execution: It provides state-of-the-art query performance on columnar data.
- Cost Efficiency: Since DuckDB runs in-process (e.g., within a Python API or a Lambda function), there is no need to maintain an expensive, always-on data warehouse cluster.
General vs. Advanced Scenarios
The architecture described above represents the general case for a modern, scalable healthcare analytics stack. It works exceptionally well for batch processing and standard reporting requirements.
However, real-world implementations often encounter special cases that require advanced options:
- Incremental Loading: For large datasets, reprocessing the entire history daily is cost-prohibitive. Implementing incremental models in dbt to process only modified FHIR resources requires robust state management and “watermark” tracking.
- Complex Extensions: FHIR allows for extensive customization via extensions. If your implementation relies heavily on complex, nested extensions, you may need custom dbt macros or User Defined Functions (UDFs) to parse them efficiently.
- Near Real-Time Latency: If analytics must be available seconds after data entry, a batch-based dbt pipeline may introduce too much latency. In such cases, a streaming architecture (using tools like Apache Flink or Spark Streaming) might be required to complement the batch layer.
Conclusion
By combining the interoperability of FHIR with the engineering rigor of dbt and the performance of DuckDB, organizations can build a data platform that is both powerful and compliant. The use of open formats like Parquet and standard storage like S3 ensures that the data remains accessible and portable, future-proofing your analytics investment.